Gallery: Sorting

sort field. However, typically, this field should not be explicitly set. Instead, bib2gls has a set of fallback fields that vary according to the entry type.
All the examples here are based on the following document:
\documentclass{article}
\usepackage[T1]{fontenc}
\usepackage[utf8]{inputenc}
\usepackage[record,stylemods=longextra,style=long-name-sym-desc]{glossaries-extra}
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB}
]
\begin{document}
\printunsrtglossaries
\end{document}
This document requires entries that are defined in mixed-entries.bib. This file has a mixture of entry types:
- Abbreviations
- These are defined with the
@abbreviationentry type and have alongandshortfield but nodescriptionfield. The defaultlong-shortabbreviation style will set thedescriptionfield to thelongform, but bib2gls doesn’t know this. Ordinarily I would make the label match the short form as closely as possible (since it makes it easier to remember when referencing it), but here I’ve used the prefix “markup-” for demonstration purposes:@abbreviation{markup-XML, short = {XML}, long = {extensible markup language} } @abbreviation{markup-HTML, short = {HTML}, long = {hypertext markup language} }Note that if you use@acronyminstead of@abbreviationyou will need to set the abbreviation style for theacronymcategory:\setabbreviationstyle[acronym]{long-short}(This must be done before\GlsXtrLoadResources.) - Mathematical Constants
- These are defined using the
@numberentry type with the name set to the symbol. The labels are the English translation of the symbols.@number{gamma, name = {\ensuremath{\gamma}}, description = {Euler's constant} } @number{pi, name={\ensuremath{\pi}}, description={Archimedes' constant} } @number{zeta3, name={\ensuremath{\zeta(3)}}, description={Apéry's constant} }Note that one of the descriptions includes a non-ASCII character (Apéry's constant). The encoding is set at the start of the .bib file:% Encoding: UTF-8
The document also needs to have the encoding set to UTF-8. This means either using a native Unicode engine (XeLaTeX or LuaLaTeX) or use the inputenc package with theutf8option. (Modern versions of PDFLaTeX will load this automatically. The example document loads it explicitly to highlight that UTF-8 support is required.) If you are restricted to using ASCII, bib2gls recognises the standard accent commands, so you can instead use:description={Ap\'ery's constant} - Terms with a Description
- These terms are defined with
@index, which doesn’t require thedescriptionfield but in this case that field has been supplied. Unlike@entry(where thenameis either required or inherited from a parent entry), the@indexfield will assume that thenamefield is the same as the label if it hasn’t been supplied.@index{zebra, description={African wild horse with black and white stripes} } @index{aardvark, description={African mammal with tubular snout and long tongue} } @index{matriculate, description={enrol or be enrolled at a college or university} } @index{zither, description={type of stringed musical instrument} } - Topic Terms
- These are terms that don’t have a description. Typically these would have child entries but they don’t in this example document. As with
@index, thenameanddescriptionfields are optional but, in this case, if thenamefield isn’t set, its value is obtained from thepluralfield. If thepluralfield isn’t set its value is obtained by appending “s” to the value of thetextfield. If thetextfield isn’t set, its assumed to be the same as the label.@indexplural{example} @indexplural{matrix,plural={matrices}}so in the first case (where the label isexample) thetextfield is set to “example” (=label), thepluralfield is set to “examples” (=text+“s”) and thenameis set to “examples” (=plural). - Metals
- These are entries that have both a description and a symbol. As with the abbreviations I would normally try to match the label with the name, but for illustrative purposes I’ve used “metal-” as a prefix. These terms are defined with
@entrythat requires both a name (either explicitly set or inherited from a parent) and description. Thesymbolfield is optional.@entry{metal-lead, name = {lead}, description={heavy metal that's soft and malleable with a low melting point}, symbol={Pb} } @entry{metal-tin, name = {tin}, description={soft, silvery metal with a faint yellow hue}, symbol={Sn} } @entry{metal-zirconium, name={zirconium}, description={grey-white, strong transition metal}, symbol={Zr} } - Card Suits
- A set of entries defined with
@symbol, these are card suit symbols. I’ve decided to prefix the labels for these with “card-” for illustrative purposes, but this maybe useful in case the labels happen to cause a conflict with future additions. (For example, I may decide to add the diamond element to the list of entries).@symbol{card-spade, name={\ensuremath{\spadesuit}}, description={spade (card suit)} } @symbol{card-heart, name={\ensuremath{\heartsuit}}, description={heart (card suit)} } @symbol{card-club, name={\ensuremath{\clubsuit}}, description={club (card suit)} } @symbol{card-diamond, name={\ensuremath{\diamondsuit}}, description={diamond (card suit)} }
The document uses the long-name-sym-desc style, which creates a three-column glossary with the name in the first column, the symbol in the second and the description in the third. Only a few terms (the metals) actually have all three columns filled. I’ve used this style for clarity for this particular example.
All entries are selected (with the selection=all option) and the resulting document just contains the glossary (shown in the image above).
Download base example: PDF (68.86K), source code (364B).
This base example lists the entries in the following order:
- aardvark
- ♣
- ♦
- ♥
- ♠
- examples
- γ
- HTML
- lead
- matrices
- matriculate
- π
- tin
- XML
- zebra
- ζ(3)
- zirconium
- zither
The default action is to sort according to the sort field. If the designated field isn’t set (which it isn’t in this case), bib2gls will use the fallback for the given entry type. The default fallback behaviour in the event of a missing sort field is as follows:
@indexand@indexpluralwill fall back on thenamefield. If that isn’t supplied, then the fallback for thenamefield is used. In the case of@indexthis is the label. In the case of@indexpluralthis is the plural. There’s no option to change the fallback field specifically for the@indexor@indexpluralentry types. (You can, however, use the more generalmissing-sort-fallback)@symboland@numberwill fall back on the label (not the name). You can change the fallback for@symboland@numberwith thesymbol-sort-fallbackoption.@entrywill fall back on thename. If that isn’t supplied, then the fallback for thenameis used (obtained from the parent). You can change the fallback with theentry-sort-fallbackoption.@abbreviationand@acronymwill fall back on theshortfield. Remember that it’s the abbreviation style that assigns thenamefield, which bib2gls doesn’t know about. If you are using a style that starts the name with the long form then it would be more appropriate to use thelongfield as the fallback. You can change the fallback for@abbreviationand@acronymwith theabbreviation-sort-fallbackoption.
If you use sort-field to use a different field for sorting then if that field is missing the fallback will be the designated fallback for that field (not the fallback for the sort field). For example, if you use sort-field=name then the abbreviations, which don’t have the name field set, will use the value of the name fallback, which also happens to be short but may be changed with the abbreviation-name-fallback option. So if you do, for example:
sort-field=name, abbreviation-sort-fallback=longthen the abbreviations will be sorted according to the
short field (which is the fallback for name) not according to long (which is now the fallback for the sort field but that field is no longer being referenced).
The effects of changing the default value of sort-field=sort is illustrated in the examples below. Where the designated field is missing, the fallback for that field is used. The final fallback used by the sort method (in the event that there is no fallback for the given field) is the entry’s label. Note that there’s a difference between a field that’s not set (which triggers a fallback) and a field that’s set but whose value is reduced to the empty string when parsed by the comparator.
Sort by Name

This example instructs the sort method to use the name field for the sort value. This just requires one extra resource option added to the base example:
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB},
sort-field={name}
]
This results in the following order (square brackets show actual sort value used):
- ♣ [“” followed by “card-club”]
- ♦ [“” followed by “card-diamond”]
- ♥ [“” followed by “card-heart”]
- ♠ [“” followed by “card-spade”]
- aardvark [aardvark|]
- examples [examples|]
- HTML [HTML|]
- lead [lead|]
- matrices [matrices|]
- matriculate [matriculate|]
- tin [tin|]
- XML [XML|]
- zebra [zebra|]
- zirconium [zirconium|]
- zither [zither|]
- γ [𝛾|]
- ζ(3) [𝜁|3|]
- π [𝜋|]
The transcript file shows the following messages:
Identical sort values for 'card-heart' and 'card-spade' Falling back on ID Identical sort values for 'card-club' and 'card-spade' Falling back on ID Identical sort values for 'card-club' and 'card-heart' Falling back on ID Identical sort values for 'card-diamond' and 'card-spade' Falling back on ID Identical sort values for 'card-diamond' and 'card-heart' Falling back on ID Identical sort values for 'card-diamond' and 'card-club' Falling back on ID
The TeX parser library has been used to interpret the values that contain commands. The results are also shown in the transcript file:
texparserlib: {}\ensuremath{\gamma} -> 𝛾
texparserlib: {}\ensuremath{\pi} -> 𝜋
texparserlib: {}\ensuremath{\zeta(3)} -> 𝜁(3)
texparserlib: {}\ensuremath{\spadesuit} -> ♠
texparserlib: {}\ensuremath{\heartsuit} -> ♡
texparserlib: {}\ensuremath{\clubsuit} -> ♣
texparserlib: {}\ensuremath{\diamondsuit} -> ♢
So you might be wondering why, for example, \ensuremath{\zeta(3)}, which has been interpreted as “𝜁(3)”, has ended up as “𝜁|3|” or why the sort method considers \ensuremath{\diamondsuit}, which has been interpreted as “♢”, and \ensuremath{\clubsuit}, which has been interpreted as “♣”, to be identical.
The answer lies in the sort method being used: sort=en-GB. This uses a locale comparator designed for text in a particular language (in this case British English). The default behaviour is to strip punctuation and to mark break points (word ends, by default) with the break point marker (the pipe or vertical bar symbol | by default). So the parentheses are stripped from “𝜁(3)” and the break point marker is inserted after each “word” resulting in “𝜁|3|”. In the case of the card suits, the Unicode symbols ♠ (U+2660), ♡ (U+2661), ♣ (U+2663) and ♢ (U+2662) are stripped leaving empty sort values (from the comparator’s point of view). These empty strings are all identical so the comparator then uses the entry labels to order those entries relative to each other but the empty sort value means they end up before “aardvark”. This is different to the default result shown at the top of this page where the label is used as the sort fallback.
Note there’s a slight difference between the way LaTeX and the TeX parser library interpret the card suit commands.
Download: PDF (68.84K), source code (384B).
Case-Insensitive Letter Sort by Name

This is a minor variation to the previous example. Here the sort method is changed to a case-insensitive letter sort:
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={letter-nocase},
sort-field={name}
]
Again the sort value is obtained from the name field (or the fallback for the name field if not set) and again the values containing commands are interpreted, but this time the value is converted to lower case, punctuation characters aren’t stripped and there are no break points. The order is now (sort value shown in square brackets):
- aardvark [aardvark]
- examples [examples]
- HTML [html]
- lead [lead]
- matrices [matrices]
- matriculate [matriculate]
- tin [tin]
- XML [xml]
- zebra [zebra]
- zirconium [zirconium]
- zither [zither]
- ♠ [♠]
- ♥ [♡]
- ♦ [♢]
- ♣ [♣]
- γ [𝛾]
- ζ(3) [𝜁(3)]
- π [𝜋]
The ordering is now obtained from a simple character code comparison of the derived sort values.
Download: PDF (68.84K), source code (392B).
Sort by Description

This example instructs the sort method to use the description field for the sort value. This just requires one extra resource option added to the base example:
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB},
sort-field={description}
]
This results in the following order (square brackets show actual sort value used):
- aardvark [African|mammal|with|tubular|snout|and|long|tongue|]
- zebra [African|wild|horse|with|black|and|white|stripes|]
- ζ(3) [Apéry's|constant|]
- π [Archimedes|constant|]
- ♣ [club|card|suit|]
- ♦ [diamond|card|suit|]
- matriculate [enrol|or|be|enrolled|at|a|college|or|university|]
- γ [Euler's|constant|]
- examples [example|]
- zirconium [grey-white|strong|transition|metal|]
- ♥ [heart|card|suit|]
- lead [heavy|metal|that's|soft|and|malleable|with|a|low|melting|point|]
- HTML [markup-HTML|]
- XML [markup-XML|]
- matrices [matrix|]
- tin [soft|silvery|metal|with|a|faint|yellow|hue|]
- ♠ [spade|card|suit|]
- zither [type|of|stringed|musical|instrument|]
There are four entries that don’t have the description field set: “HTML” and “XML”
(defined with @abbreviation) and “examples” and “matrices” (defined with
@indexplural). There’s no fallback for the description field, so the label is used instead if it’s missing.
Download: PDF (68.86K), source code (391B).
Sort by Symbol
This example instructs the sort method to use the description field for the sort value. This just requires one extra resource option added to the base example:
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB},
sort-field={symbol}
]
Note that this example is using a locale comparator not a letter comparator. This results in the following order (square brackets show actual sort value used):
- aardvark [aardvark|]
- ♣ [card-club|]
- ♦ [card-diamond|]
- ♥ [card-heart|]
- ♠ [card-spade|]
- examples [example|]
- γ [gamma|]
- HTML [markup-HTML|]
- XML [markup-XML|]
- matriculate [matriculate|]
- matrices [matrix|]
- lead [Pb|]
- π [pi|]
- tin [Sn|]
- zebra [zebra|]
- ζ(3) [zeta3|]
- zither [zither|]
- zirconium [Zr|]
Only three of the entries actually have the symbol field set. There’s no fallback for that field so the label is used.
Download: PDF (68.86K), source code (386B).
Altering the Fallback
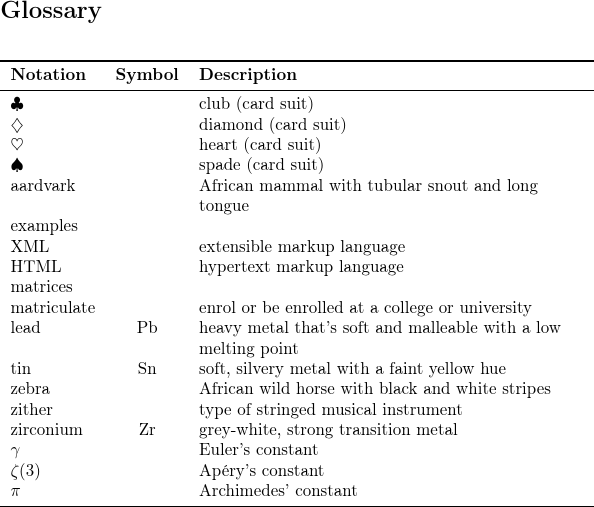
In this example, instead of selecting a particular field to sort by (such as name) I’ve changed the sort fallback settings:
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB},
symbol-sort-fallback={name},
abbreviation-sort-fallback={long},
entry-sort-fallback={symbol}
]
No entries have the sort field set so they will all use the fallback field according to their entry type. In this case, symbols (@symbol and @number) will fallback on the name, abbreviations will fallback on the long field and general entries (@entry) will fallback on the symbol field. The @index and @indexplural terms still fallback on the name. This results in the following order (square brackets show actual sort value used):
- ♣ [“” followed by “card-club”]
- ♦ [“” followed by “card-diamond”]
- ♥ [“” followed by “card-heart”]
- ♠ [“” followed by “card-spade”]
- aardvark [aardvark|]
- examples [examples|]
- XML [extensible|markup|language|]
- HTML [hypertext|markup|language|]
- matrices [matrices|]
- matriculate [matriculate|]
- lead [Pb|]
- tin [Sn|]
- zebra [zebra|]
- zither [zither|]
- zirconium [Zr|]
- γ [𝛾|]
- ζ(3) [𝜁|3|]
- π [𝜋|]
As with the sort by name example, the card suit characters are discarded by the locale sort comparator leaving an empty string (which puts them before “aardvark”). This means those four entries have identical sort values (“”) and so are ordered relative to each other according to their labels.
The abbreviations are now ordered according to their long form. This may be more appropriate if the style chosen shows the long form (or long followed by short) as the name.
The metals (lead, tin and zirconium) are now ordered according to their symbol so, for example, “zirconium” now comes after “zither”.
Download: PDF (68.84K), source code (461B).
Blocks
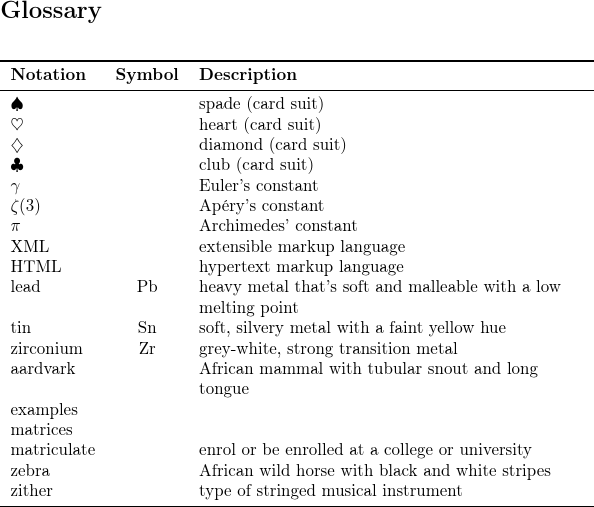
Each resource command (\GlsXtrLoadResources) sorts and collates the selected entries and writes their definitions to a .glstex file. The \printunsrtglossary command (used internally by \printunsrtglossaries) simply iterates over the entry labels according to their definition (from the glossaries package’s point of view). That is, according to the order they are written in the .glstex files. This means that if you have multiple instances of \GlsXtrLoadResources for the same glossary then that glossary listing will have sub-sorted blocks (where the blocks are in the same order as the corresponding \GlsXtrLoadResources commands). There need not necessarily be any visual separation between those blocks (although that can be added, see Logical Glossary Divisions (type vs group vs parent)).
In this example, the symbols (@symbol and @number) are first sorted (case-sensitive with name as the sort fallback), then the abbreviations are sorted (locale with long as the sort fallback), then the metals (@entry) are sorted (case-insensitive letter with symbol as the sort fallback), then finally the terms (@index and @indexplural) are sorted (locale).
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={letter-case},
symbol-sort-fallback={name},
match={entrytype={symbol|number}}
]
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB},
abbreviation-sort-fallback={long},
match={entrytype=abbreviation}
]
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={letter-nocase},
entry-sort-fallback={symbol},
match={entrytype=entry}
]
\GlsXtrLoadResources[
src={mixed-entries},
selection=all,
sort={en-GB},
match={entrytype={index|indexplural}}
]
This results in the following order (square brackets show actual sort value used):
- ♠ [♠]
- ♥ [♡]
- ♦ [♢]
- ♣ [♣]
- γ [𝛾]
- ζ(3) [𝜁(3)]
- π [𝜋]
- XML [extensible|markup|language|]
- HTML [hypertext|markup|language|]
- lead [pb]
- tin [sn]
- zirconium [zr]
- aardvark [aardvark|]
- examples [examples|]
- matrices [matrices|]
- matriculate [matriculate|]
- zebra [zebra|]
- zither [zither|]
Download: PDF (68.84K), source code (841B).